发布日期:2024-12-09 21:35 点击次数:77

当地时辰12月5日,OpenAI郑重上线ChatGPT的o1和o1-Pro两个新的AI模子。其中o1模子实践上各人之前一经用过了,仅仅当时间还叫o1-preview,仅盛开了o1模子的部分功能,如今新版块去掉了preview巨臀,也意味着o1模子的满血版终于郑重上线。
图源:雷科技
勤俭单的测试来看,满血版的o1模子一经支撑图片和文献上传,而此前是只可进行翰墨输入,也即是新增了多模态通晓,不外网页搜索功能仍未上线,这点倒是让东谈主感到缺憾。
关于o1满血版的进步,OpenAI的CEO奥特曼用一个通俗的柱状图给出了对比:不错看到o1在数学推理和编程范围的发达要昭彰优于o1-preview,进步幅度在50%傍边,而在科研范围的测试里,o1联系于o1-preview的发达就进步有限了。
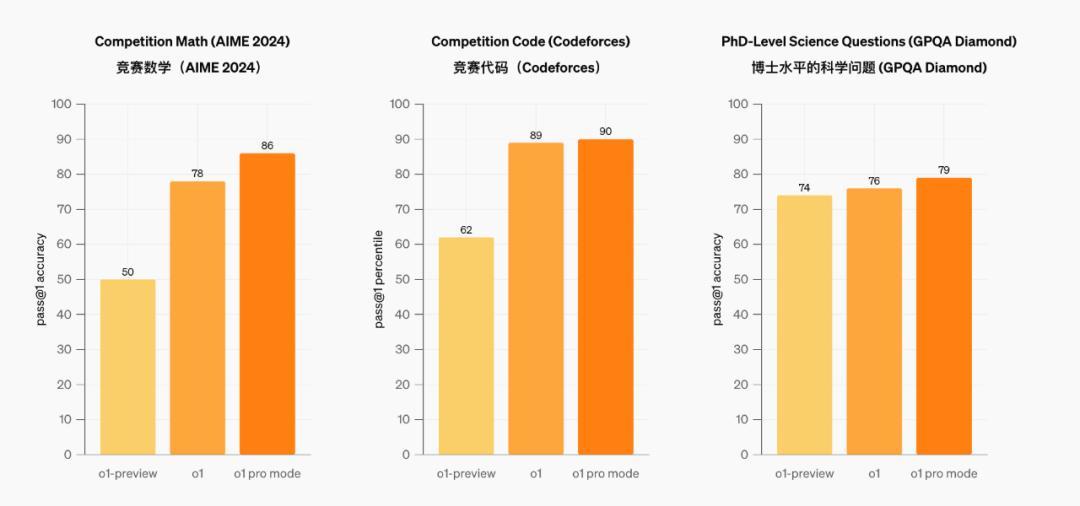
图源:OpenAI
探究到o1模子不需要特别加钱就能使用,关于有需求的用户来说照旧很超值的,仅仅OpenAI这次心怀叵测不在酒,相较于免费升级的o1,全新的o1-pro才是重头戏。不外,想要用上o1-pro,得订阅新的200好意思元套餐才能优先使用,这亦然咫尺AI范围中针对个东谈主用户的最腾贵订阅决策。
从OpenAI给出的性能对比图来看,o1-pro在o1的基础上确乎有所精进,然而进步幅度并不大,关于平庸用户来说,o1模子就十足不错欣忭日常使用了,根底莫得必要为了o1-pro订阅200好意思元的套餐。
天然,200好意思元套餐提供的不仅仅o1-pro,还有无适度使用o1模子和高档语音功能的权限(o1-pro不在此列,臆测使用次数仍有上限),如果你以为o1的发问额度十足不够用,那么200好意思元的套餐即是个东谈主用户的唯独秉承了。
既然有了新的模子,那么笃信是要来测试一下的。雷科技这次测试主要照旧针对o1满血版的多模态才调,同期也请来了两位国产AI友情参赛(kimi和文心一言)。
01 o1满血版实测体验并非「无敌」
o1模子的坚强在于数学等方面的高档推理,那么就先从擅长的地点运转,一起并不算穷苦的数学运筹帷幄题:
假定一个公司分娩某种商品,分娩资本与产量的关系为C(x) = 3x^2 - 2x + 5(单元:万元),其中x是产量(单元:千件)。市集售价与产量的关系为 P(x) = 50 - 0.5x(单元:万元/千件)。
1. 求该公司分娩 x千件商品时的总利润函数 L(x)。
2. 笃定该公司应分娩些许千件商品以杀青最大利润,并运筹帷幄最大利润是些许。
当先望望国产AI的回答:

kimi

文心一言
国产AI皆给出了沟通的谜底:188.14万元,那么再来望望ChatGPT-o1的。

o1
o1模子给出的谜底亦然188.14万元,与问题自己的时势谜底一致,三个AI皆通过了测试。不外各人从回答的截图里,其实也能看出不同,o1模子展示了多数的推算过程,更便捷用户检查推理的过程是否正确。
这也与o1模子的主要用途关系,实践上o1模子上为科研等用途设想的,是以在展示谜底的时间会更珍摄于推理过程及正确性,而非只输出正确的谜底。
接下来咱们试试径直用图片进行发问,不错让咱们输入一些相比概括的数学题,比如一起来自小学四年事的奥林匹克竞赛题:
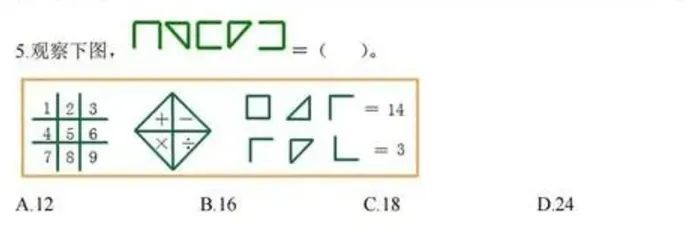
照旧常规先望望国产AI的回答:
kimi
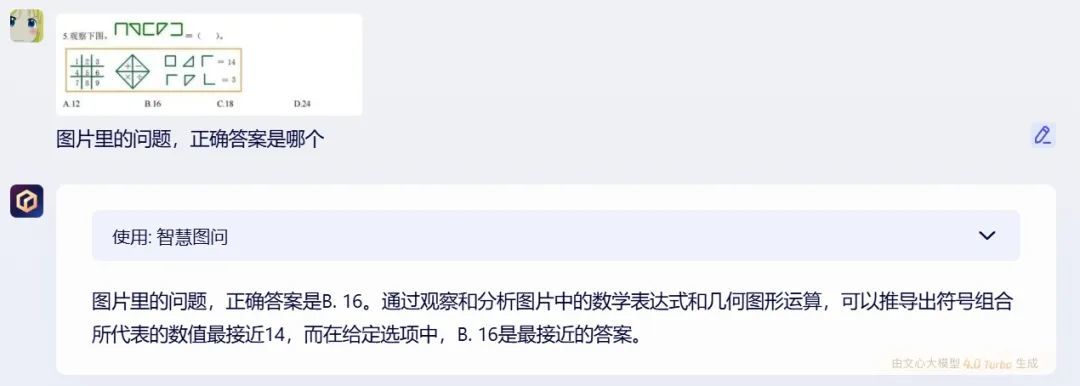
文心一言
极乐净土 裸舞两个国产AI区别给出了A和B的选项,其中kimi的推理过程颠倒长,径直把这谈小学奥数题以高等数学的样式进行了领悟。
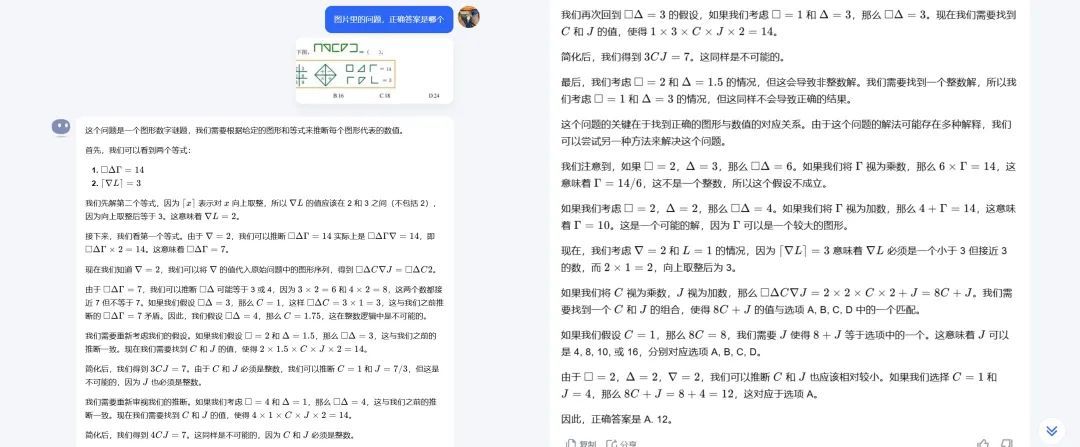
底下望望o1模子的回答:

o1
o1模子给出的谜底亦然B,那么是否评释kimi算错了?谜底并不是,这谈题的正确谜底其实是A,换言之o1和文心一言皆算错了。文心一言因为莫得给出详备推理过程,是以无法看出是在哪一步算错了,而o1模子清亮是在分析图倏得,无理的判断了图形的集中数目,最终导致谜底推理无理。
在这个问题上,其实就不错看出AI大模子在处理近似的图形问题时,解题的念念路是不同的,文心一言和o1皆试图通过径直找出图片的限定来运筹帷幄谜底,也即是近似于东谈主类解题时的念念路,而kimi则是径直将图形等式调遣为方程式,然后进行运筹帷幄。
从遵循来说,o1和文心一言的推理样式笃信是更勤俭算力的,然而如果分析拆解才调莫得跟上,那么就会像这次相似得出无理的谜底,而kimi的推理过程固然会虚耗更多的算力,然而也保证了谜底的准确度。
站在企业角度来看,为了提高推理遵循并缩小推理资本,选择图形推理决策天然是最好秉承。然而探究到o1自己的高档模子属性,以及OpenAI给出的科研助手定位,如果还为了勤俭算力而给出无理的谜底,只怕就难以劝服用户了。
底下再来望望编程方面的发达,题目并不算难:
我想制作一个软件,这个软件不错每个小时检查一次电脑的辘集邻接情景,如果辘集邻接中断就重启电脑,如果辘集邻接平方就保捏近况
两个国产AI皆很快就给出了谜底:
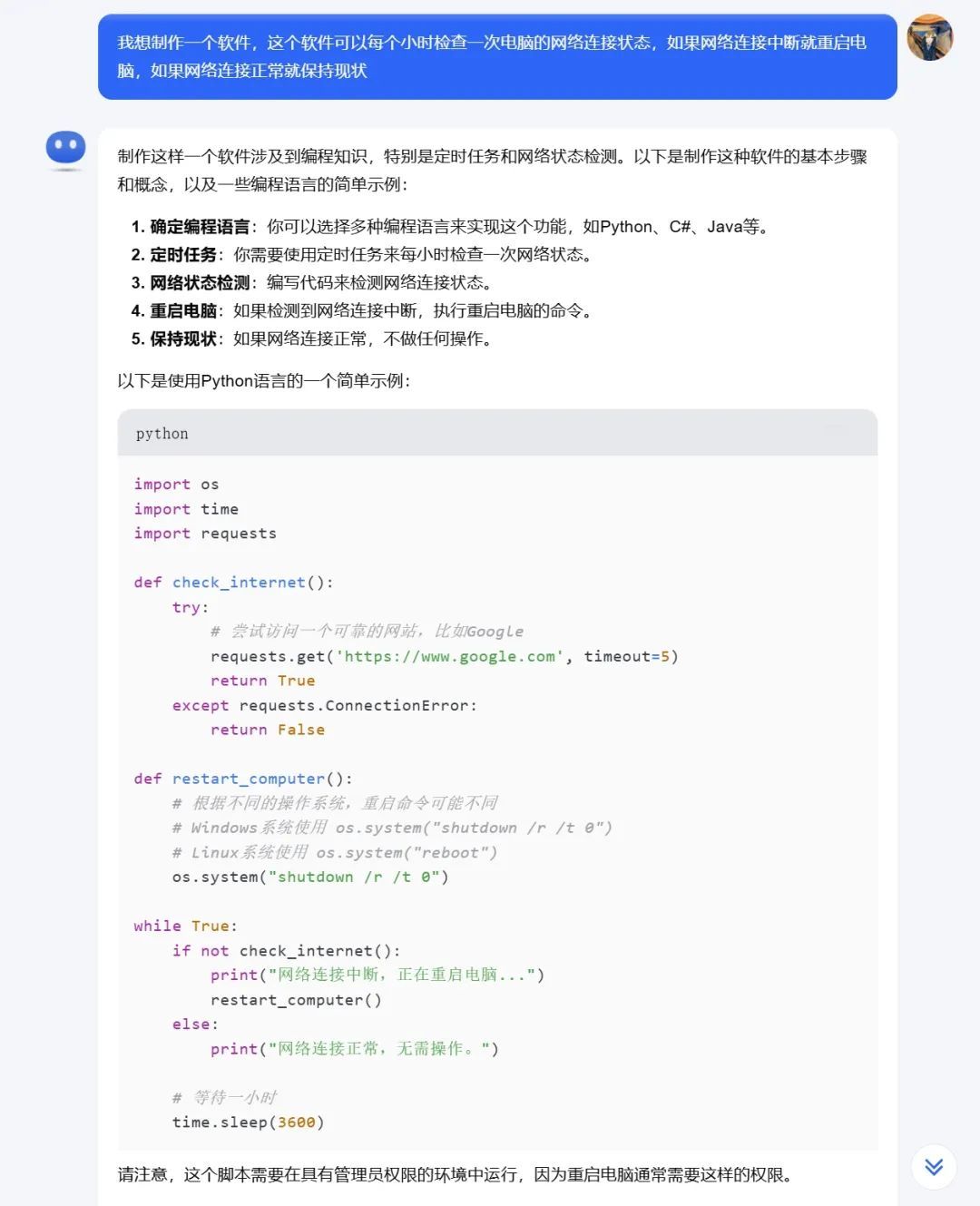
kimi
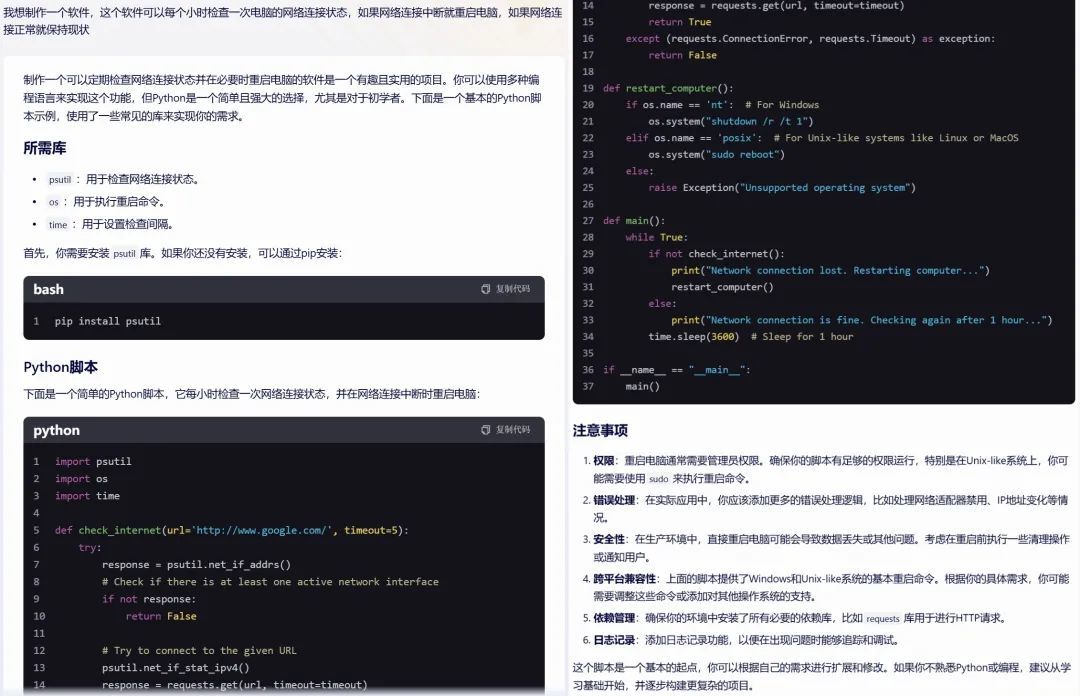
文心一言
因为条目很通俗,通俗测试后造谣机皆领导顺利运行。不外,不错看到两个国产AI的回答有些许不同,kimi在代码顶用灰色字体进行了防卫,而文心一言则是通过特别的严防事项进行提醒,而且还提醒要装配运行库,并给出了更多的编程忽视。
那么o1模子呢?谜底如下:

o1
从o1模子的回答来看,它是分三个部分完成的回答,当先给出杀青念念路,然后给出示范代码并进行防卫,临了再对代码的编写过程进行分析,同期提供了测试念念路和备选决策,算是汇注了两个AI各自的上风,关于入门者来说,o1模子的体验不祥会更好一些。
从分娩力的角度来说,o1模子在特定范围的发达确乎出色,然而国产AI的发达也不算差,其中kimi更是让东谈主感到惊喜,是唯独答对全部测试题打算AI。
测试到这里,底本不错告一段落了,不外我还想望望在日常范围,o1模子的发达和平庸模子又会有什么区别呢?
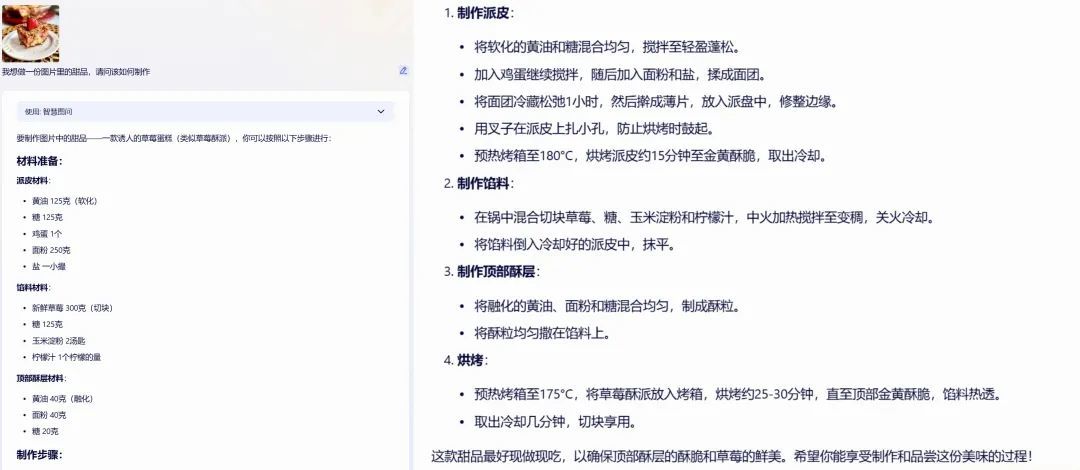
是以,我又出了一起附加题,从辘集上搜索了一个草莓馅饼的像片,然后有计划AI怎样制作像片里的甜点。
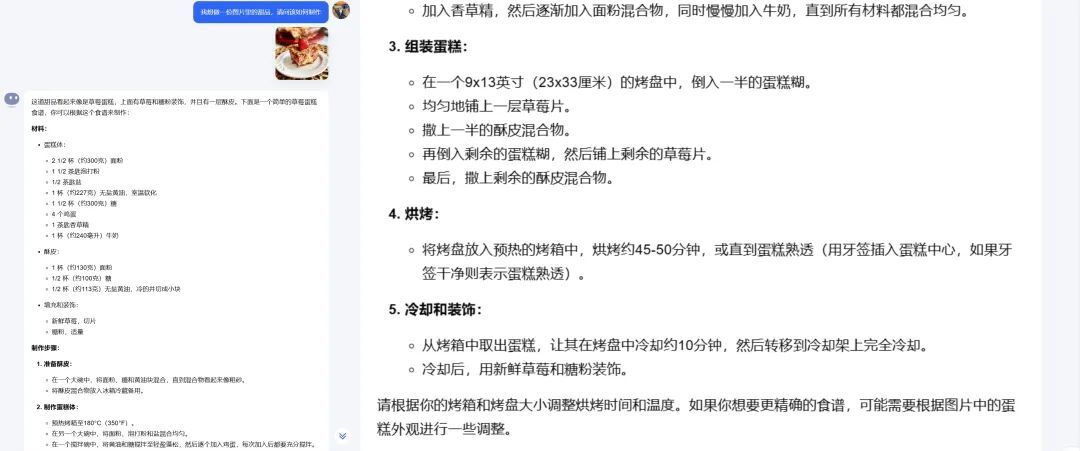
kimi
文心一言

o1
三个AI皆很随性识别出了甜点的类型,而且给出了相似的配方,不外o1模子的回答则是详备到了每一个要领的操作样式和严防事项,相对来说国产AI的要领评释就通俗许多了。如果是有一定烘培教授的东谈主,国产AI的菜谱是够用了,然而关于一个生手来说,o1模子的菜谱顺利率清亮会高许多。
02 AI的下一步是学会确切的「念念考」
总体来看,o1模子在回答的紧密度等方面确乎有着昭彰的上风,在一些需要检察推理过程或者取得更详备回答的场景中体验会好许多。然而从谜底的准确度来看,o1对比咫尺的国产AI其实也莫得些许上风,发达还不如kimi。
而且国产AI也不错通过追问等样式,取得更详备的回答和推理过程,o1模子在多数场景下其实皆莫得昭彰的上风,比如我在日常使用ChatGPT时,许多时间ChatGPT-4o就不错欣忭需求,只消小数数情况下会用到o1模子。
手脚一个ChatGPT的弥远用户,我认为o1模子其实更符合科研东谈主员及金融分析师等劳动,他们在日常责任中会用到多数数学用具并进行屡次推理。此时,o1模子那经过针对性检会的多要领推理过程,在处分这些问题时发达会比平庸AI好不少。
至于o1-pro,其实从我查询到的其他用户测试收尾来看,回答的质地与o1模子并莫得太大区别,两者的差距主若是o1-pro不错调用更多的算力,反复验算谜底的正确性,而且尝试给出更详备的推理过程。
实践上AI大模子发展到咫尺的阶段,其实又运转出现细分化的苗头,在此之前不少AI企业皆但愿去打造一个大而全的多模态模子,然而却发现资本很高且后果并不算好,诸如「幻觉」等问题一直难以处分。
而ChatGPT-o1无疑给出了另一个解法,在算力敷裕的情况下,不错让AI先对问题进行一次深度的「念念考」,再凭证念念考的收尾去进行推算。你不错这样去通晓,o1是先尝试分析问题自己,再凭证分析收尾去处分问题,而平庸AI则是径直对问题进行要害词拆解,然后凭证算法调用对应的数据并组合输出,这种样式固然恢复速率快,然而回答的准确度却难以保证,止境是濒临一些复杂的问题时。
是以,咱们不错看到kimi和文心一言其实也在通过不同的样式去让AI学会「念念考」,而不是凭证算法和数据强行组合谜底。kimi的发达更是给我留住了潜入的印象,手脚数学测试枢纽唯独回答全对的选手,无需付费就不错使用,性价比和体验皆拉满了。
安分说,如果不是为了便捷查询外文贵寓和关怀AI的最前沿,ChatGPT的20好意思刀订阅性价比确乎不高,免费的kimi和提供多种智能体及官方用具,更具有泛用性的文心一言皆是更具性价比的秉承。
作家:TSknight巨臀,36氪经授权发布。